Assume temporary IAM credentials in AWS Glue jobs
In this post we will take a look at how to assume an IAM Role and use temporary credentials inside an AWS Glue job. Why? Because currently a Glue job only supports a single IAM Role. In a multi-tenancy environment you may want to assume a Role with scoped permissions only to a specific S3 bucket for that tenant. The tenant name can then be passed as a job parameter rather than having a job per tenant.
Setting up the pre-reqs
-
Create an S3 bucket to be used as the source/destination for the glue job e.g.
my-glue-data -
Create an IAM Role using the
AWS Glueuse case namedmy-glue-job-role. This Role will be assigned to the Glue job itself. Add an inline policy to give access to the glue assest S3 bucket (where Glue will pull the job script from).{ "Version": "2012-10-17", "Statement": [ { "Sid": "GlueAssets", "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::aws-glue-assets-<account-id>-<region>/*" } ] }Note: if you want the job to log to CloudWatch you will also need to give CloudWatch logs permissions here too
-
Create a second IAM Role, this time with a Custom trust policy which will allow it to be assumed by the
my-glue-job-role.{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowGlueAssume", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:role/my-glue-job-role" }, "Action": "sts:AssumeRole" } ] } -
Give the second IAM Role permissions to access the
my-glue-databucket.s3:PutObjectands3:GetObjectshould be sufficient. Name this rolemy-glue-assumed-role. -
Go back to the
my-glue-job-roleand edit the inline policy permissions to addsts:AssumeRoleto themy-glue-assumed-role.{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::123456789012:role/my-glue-assumed-role" } }
Now we have everything in place to create the Glue job. To recap we have two IAM roles:
my-glue-job-role= permissions to be assumed by the Glue service and access to assume the role my-glue-assumed-role. This does not have any S3 permissions.my-glue-assumed-role= permissions to access the S3 bucket containing the data
Creating the Glue job
-
In the AWS Glue Console create a new job. You can start with the Visual source and target using Amazon S3 for both.
-
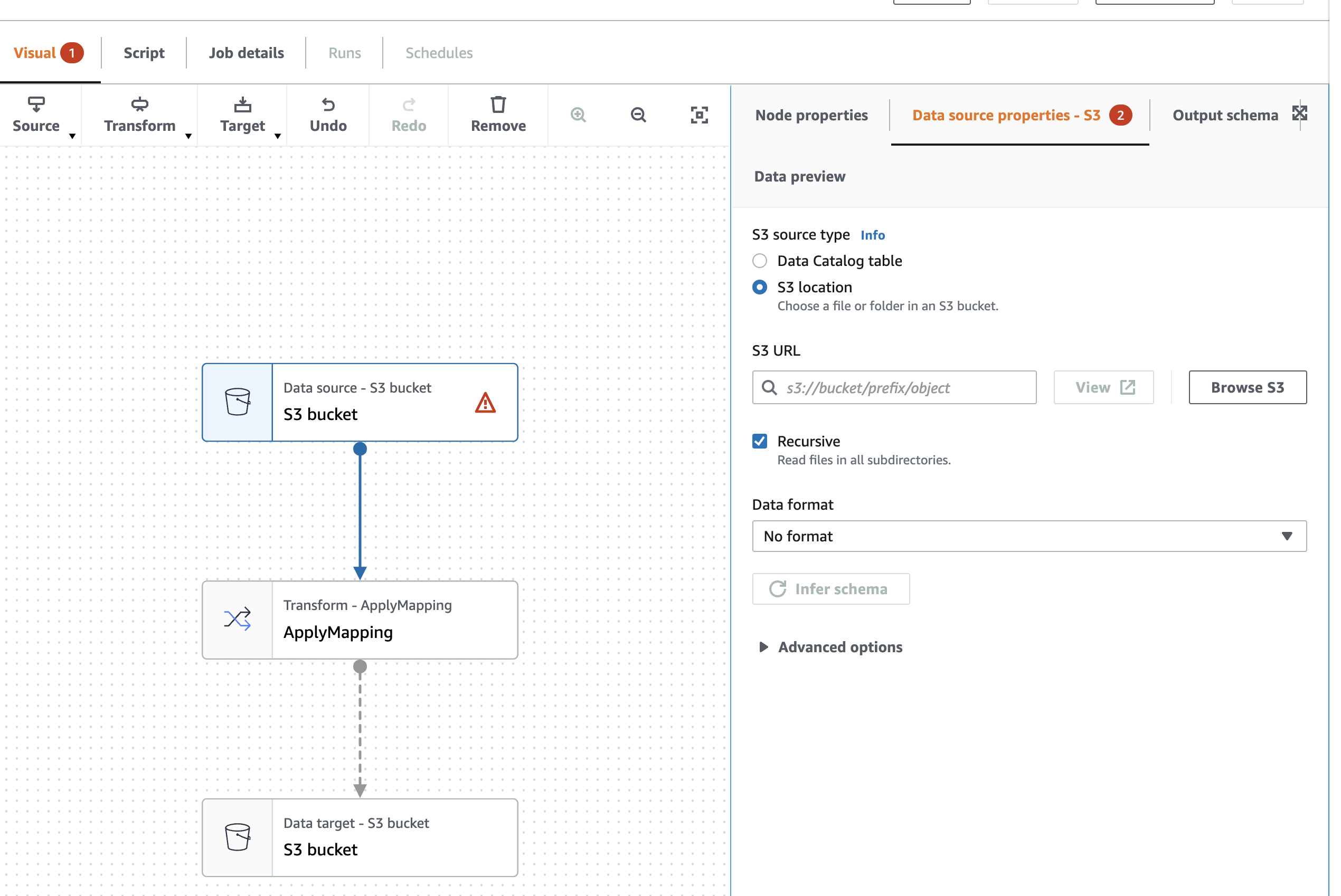
Set your desired source path, destination path and any transformations required (this article does not cover setting this up in detail).
-
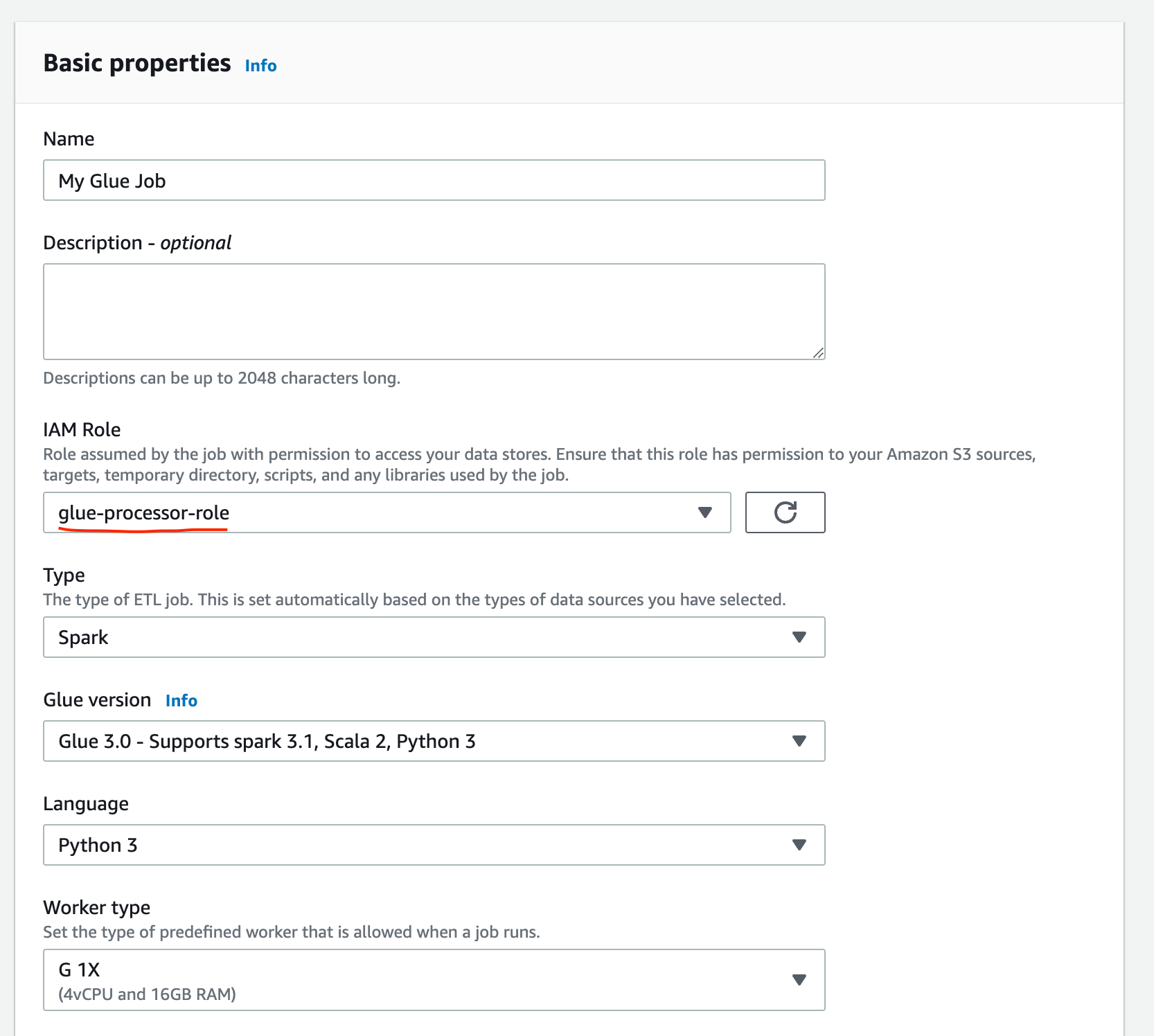
Under Job details set the IAM Role to the
my-glue-job-roleRole created earlier. Give the job a name and click Save. -
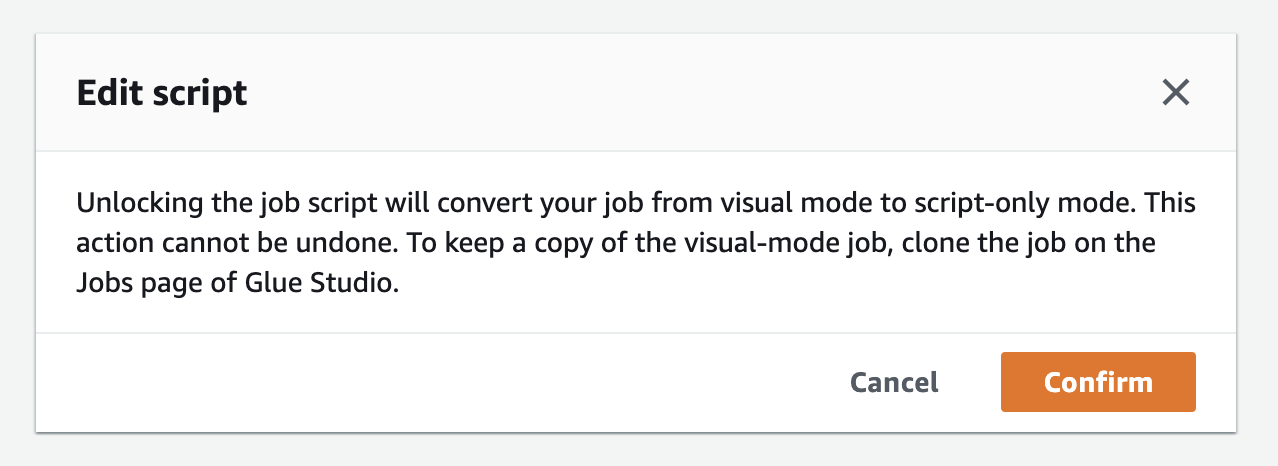
Now select the Script tab and click Edit script. You will recieve a warning - clikc Confirm. We only needed the visual editor to generate boiler plate code.
-
Your script should look something like this:
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node S3 bucket S3bucket_node1 = glueContext.create_dynamic_frame.from_options( format_options={"multiline": False}, connection_type="s3", format="json", connection_options={"paths": ["s3://my-glue-data/MOCK_DATA.json"]}, transformation_ctx="S3bucket_node1", ) ... -
First add a part near the top of the script to assume the IAM role using boto3:
import boto3 sts_connection = boto3.client('sts') response = sts_connection.assume_role(RoleArn='arn:aws:iam::123456789012:role/my-glue-assumed-role', RoleSessionName='GlueTenantASession',DurationSeconds=3600) credentials = response['Credentials'] -
Next add a section to set those credentials in the SparkContext:
sc._jsc.hadoopConfiguration().set('fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider') sc._jsc.hadoopConfiguration().set('fs.s3a.access.key', credentials['AccessKeyId']) sc._jsc.hadoopConfiguration().set('fs.s3a.secret.key', credentials['SecretAccessKey']) sc._jsc.hadoopConfiguration().set('fs.s3a.session.token', credentials['SessionToken']) -
Finally change any instances using the
s3://client to use thes3a://client. -
The final script should look something like this:
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job import boto3 sts_connection = boto3.client('sts') response = sts_connection.assume_role(RoleArn='arn:aws:iam::123456789012:role/my-glue-assumed-role', RoleSessionName='GlueTenantASession',DurationSeconds=3600) credentials = response['Credentials'] args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() sc._jsc.hadoopConfiguration().set('fs.s3a.aws.credentials.provider', 'org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider') sc._jsc.hadoopConfiguration().set('fs.s3a.access.key', credentials['AccessKeyId']) sc._jsc.hadoopConfiguration().set('fs.s3a.secret.key', credentials['SecretAccessKey']) sc._jsc.hadoopConfiguration().set('fs.s3a.session.token', credentials['SessionToken']) glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node S3 bucket S3bucket_node1 = glueContext.create_dynamic_frame.from_options( format_options={"multiline": False}, connection_type="s3", format="json", connection_options={"paths": ["s3a://test-glue-bucket/MOCK_DATA.json"]}, transformation_ctx="S3bucket_node1", ) ... -
Once you have finished editing the script run the job. The job should complete successfully with no AccessDenied errors. You should find your output files on the S3 bucket.
You could extend this further by using a Session Policy with the AssumeRole. This will allow you to dynamically generate a scoped policy at runtime, for example using a job parameter passed in when the job is run.