Understanding the Lambda execution environment and using it correctly!
When you begin using AWS Lambda you may start wondering what is going on behind the scenes. It’s important to understand the Lambda execution environment and it’s lifecycle in order to make sure your code is efficient and reliable.
This post will look at how Lambda execution environment works, it’s lifecycle, and how to make sure you are coding your functions to use it correctly.
What is an execution environment?
When you invoke your function the code needs somewhere to execute in a secure and isolated way. Before the first invoke there will be nowhere available for this to happen, so on the first request Lambda will create an execution environmnet!
This involves creating a lightweight micro-virtual machine (microVM) using a virtulization technology called Firecracker. This microVM is known as a worker. Firecracker is open source technology, based on KVM, and created by AWS to launch microVMs on bare-metal hardware (EC2 Nitro instances) in a fraction of second (less than 125ms).
It means better security and hardware isolation that running in a container, but much faster to initialise that a standard VM as there is a simplified device mode with no BIOS and no PCI.
The microVM runs with your configured memory setting using the runtime you defined. This could be using an AWS managed runtime, for example Python 3.9 running on Amazon Linux 2, or your own custom runtime. It could also be a container image using your own defined Linux guest OS and depenencies.
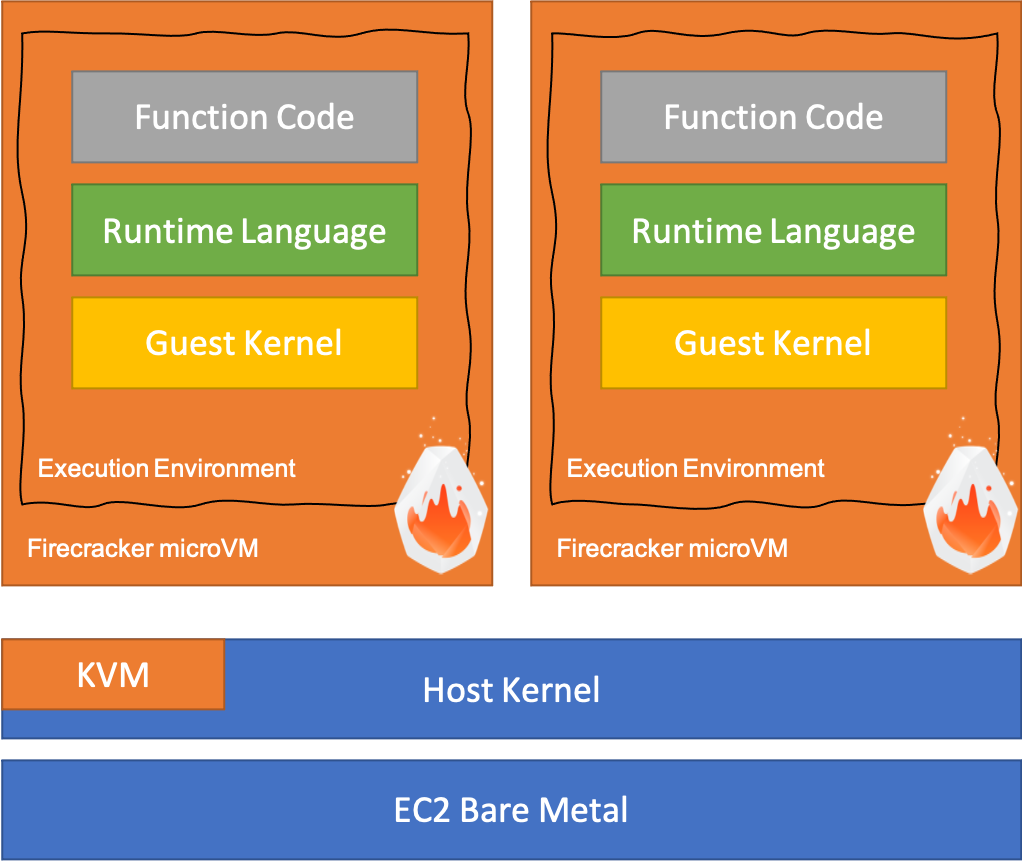
One key thing to know is that an execution environment can only handle one request at once. So if multiple invocations happen at the same time, then more microVMs are required!
Execution environment lifecycle
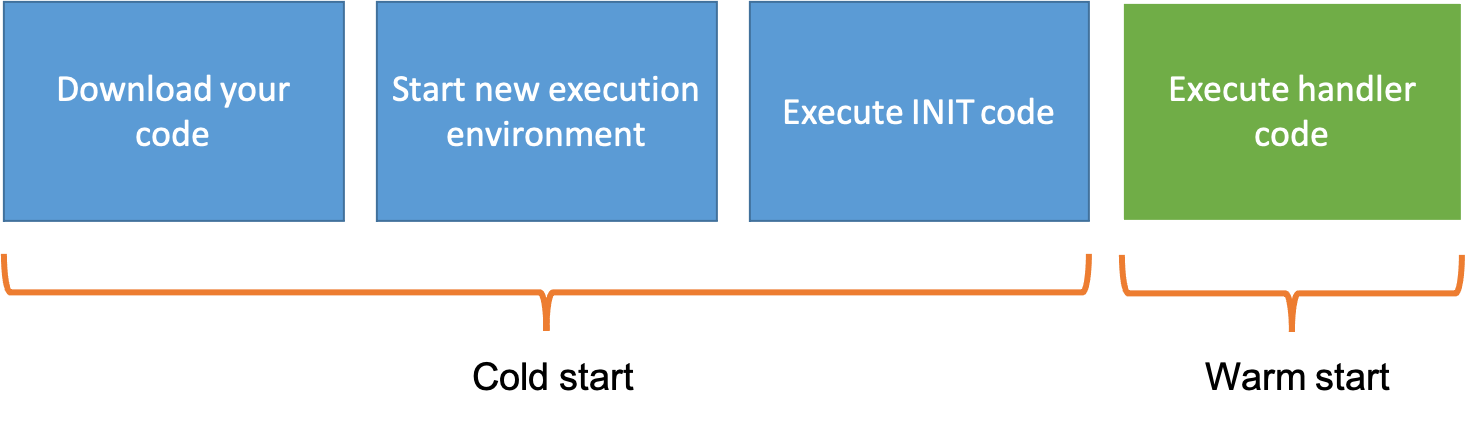
Now let’s think about the life of an execution environment. When a invocation comes into Lambda and there isn’t an existing execution environment, one will be created. Once this is done your Lambda code will execute which includes running the Init code and the Handler code. The Init code is everything that is outside of the handler funtion.
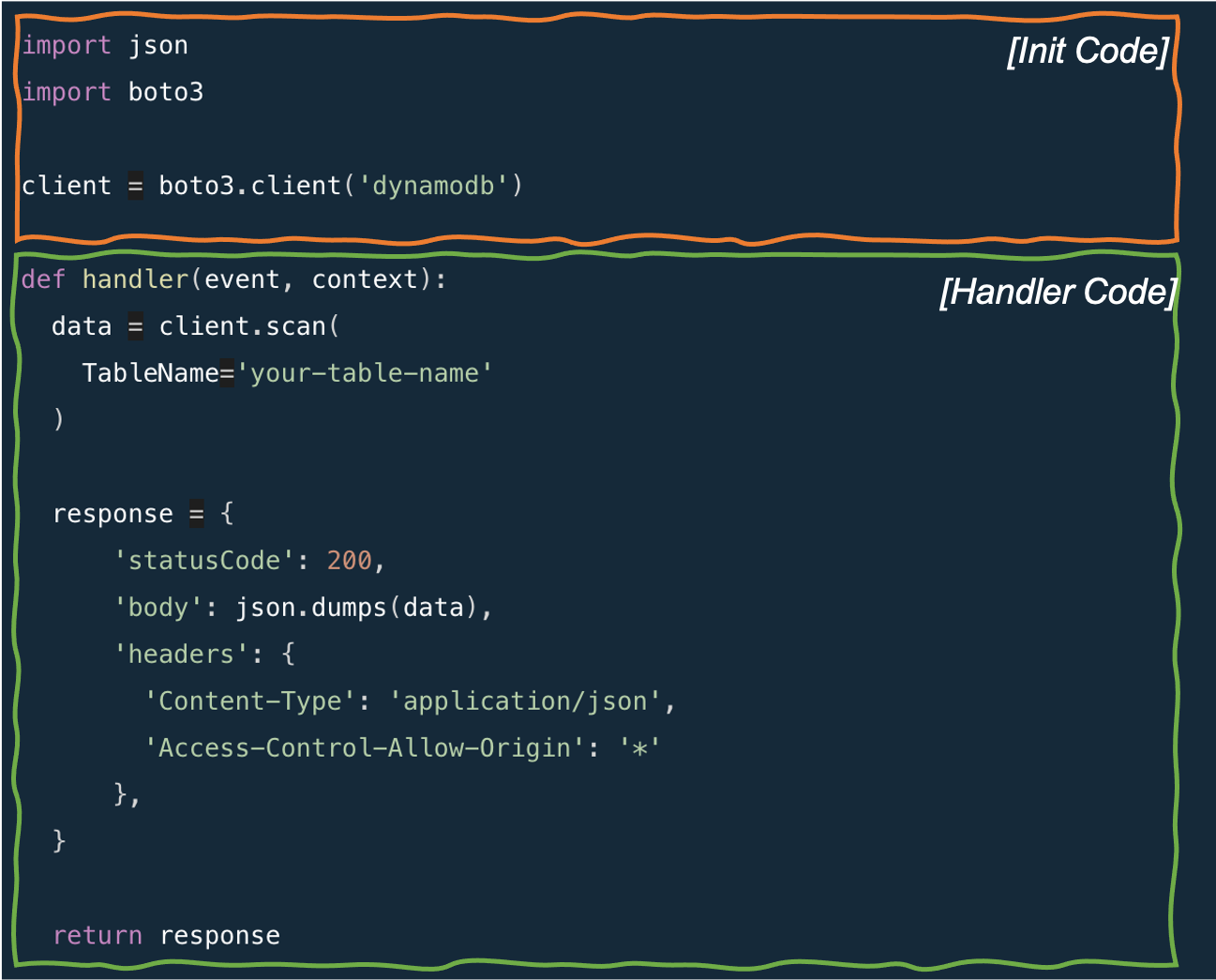
Applying this to a sample Python Lambda function we can see which parts run during Init and which as part of a warm start.
Although execution environments can only run once execution at any time, they can be reused. After your code has finished executing the environment will not be shutdown immedietely. Instead it will remain available for further requests, which typically will response with a lower latency due to a wamred environment already being available.
If a request comes in and all execution environments are busy then a new one will be created.
Workers have a maximum lease lifecycle of 14 hours, but could be terminated much earlier than this. This is not something you as the customer have any control over.
Why does all this matter for my coding?
Running code outside the handler function means it doesn’t need to re-run on a warm start. This can improve the efficiency of your code, and therefore reduce the invocation time and there reduce the costs!
Things you should considering doing outside the handler:
- importing dependencies
- initalising SDK clients
- creating connection a to a database
- loading external parameters e.g. from Parameter Store or Secrets Manager
- loading function code into memory
- downloading files from S3 into /tmp
Because the memory state and /tmp file system will be saved and re-used then caching values for subsuquent invocations can really help optimize the performance of the function. Just be aware that your values may become out of date if they change regularly.
Another consideration is when initialising variables. Doing this incorrectly can lead to inconsistent results. Take the below sample code.
import time
count = 0
def lambda_handler(event, context):
global count
count = count + 1
time.sleep(1) # sleep to help test concurrency
return count
With a rate of 1 request/sec the results are as follows:
- Invoke1: 1
- Invoke2: 2
- Invoke3: 3
- Invoke4: 4
- …
However is the req/sec is increased more execution environment are spun up and results look every different:
- Invoke1: 1
- Invoke2: 1
- Invoke3: 1
- Invoke4: 2
- Invoke5: 1
- …
The above will vary as you cannot control how Lambda is allocating requests to execution environments. It does demonstrate that you need to be careful where you declare and use variables within your code. Otherwise you could end up with a situation where you end up leaking data left over in memory from a previous execution. Sometimes in a multi-tenented environment you may prefer to have a function per tenant to avoid this situation from occuring.
Pre-warming execution environments
It is possible to use a feature of Lambda called Provisioned Concurrency to create pre-warmed execution environments for your function. This eliminates cold starts and means the mircoVMs are up and run with Init code already run.
You configure provisioned concurrency on a particular Lambda version or alias. You define a number of concurrent execution environments to keep running. This comes at an additional hourly cost and means that you no longer get the benefit of not paying for idle with Lambda.
There is the option to add Application Auto Scaling to automatically adjust provisioned concurrency based on a schedule or defined metric.
How do I know when a cold start occured?
The easiest way to to look into the logs in CloudWatch Logs. An invocation that encoutered a cold start will report an Init Duration value in the REPORT log line.
For example:
REPORT RequestId: 28e410e6-722c-4c5a-90e5-b4dc39abce29 Duration: 2003.82 ms Billed Duration: 2004 ms Memory Size: 128 MB Max Memory Used: 35 MB Init Duration: 113.10 ms
This shows that the Init took 113.10ms.
A warm invocation will not report a Init Duration.